
개발자 항해
데이터를 그룹화 본문
1. Group화

2. Group by 절
3. HAVING 절
SELECT [column,] group_function(column)...
FROM table [WHERE condition]
[GROUP BY group_by_expression]
[HAVING having_expression]
[ORDER BY column];
4. GROUP BY에 ROLLUP 나 CUBE 사용
1) rollup
기본 그룹화와 소계값을 구해주는 연산자
-rollup(N개 컬럼) => N+1개의 그룹화한 결과가 반환됨
rollup(dept_id)
=> (dept_id),(전체)
=> rollup (컬럼 1개) : N+1 = 1 + 1 =2번의 그룹화
rollup(dept_id, job_id)
=> (dept_id,job_id),(dept_id),(전체)
=> rollup(2개 컬럼) : 2+1 = 3번의 그룹화
rollup(dept_id, job_id, mgr_id)
=> (dept_id, job_id, mgr_id),(dept_id,job_id),(dept)id),(전체)
=> rollup(3개 컬럼) : 3+1 = 4번의 그룹화
[case1] select dept_id, job_id, sum(salary)
from employees
group by dept_id,job_id
union all
select dept_id, to_char(null), sum(salary)
from employees
group by dept_id
union all
select to_number(null),to_char(null), sum(salary)
from employees;
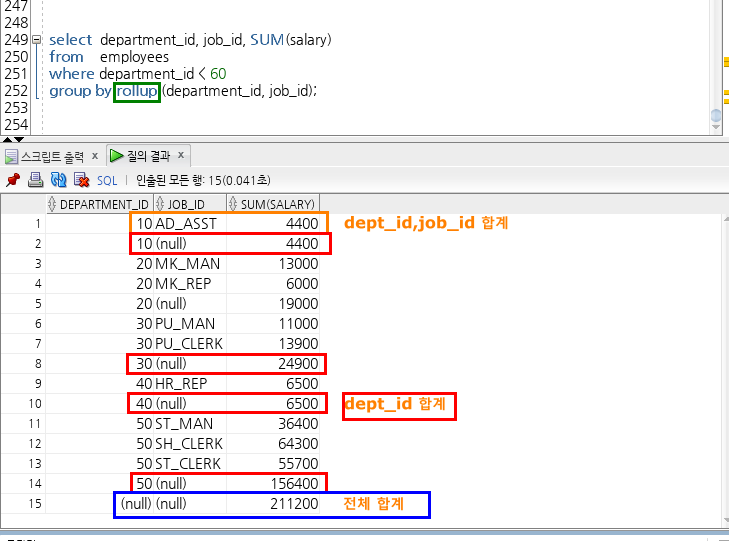
[case2] select dept_id, job_id, sum(salary)
from employees
group by rollup(dept_id, job_id);
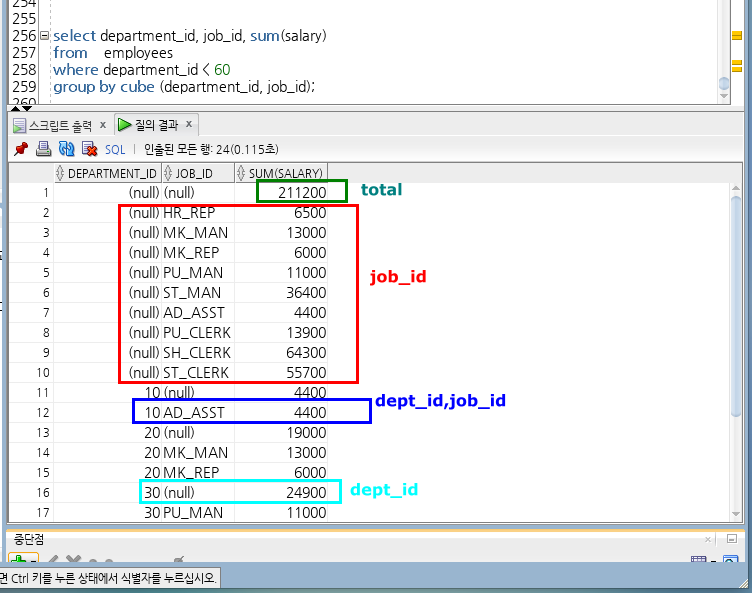
2) cube
기본 그룹화한 결과와 모든 조합에 대한 소계값을 구해주는 연산자
cube(N개 컬럼) => 2의 N승개의 그룹화한 결과가 반환됨.
cube(dept_id)
=> (dept_id),(전체)
=> cube(1개 컬럼) : 2의 1승 = 2번의 그룹화
=> cube(2개 컬럼) : 2의 2승 = 4번의 그룹화
cube(dept_id,job_id)
=> (dept_id, job_id) , (dept_id),(job_id),(전체)
cube(dept_id,job_id,mgr_id)
=>(dept_id,job_id,mgr_id),
(dept_id,job_id),(job_id,mgr_id),(dept_id,mgr_id),
(dept_id),(job_id),(mgr_id),(전체)
=> cube(3개 컬럼) : 2의 3승 = 8번의 그룹화
(ex1) 부서별 급여 합계와 전 사원의 급여 합계를 출력하시오.
[case1] select dept_id, sum(salary)
from employees
group by dept_id
union all
select to_number(null), sum(salary)
from employees;
[case2] select dept_id, sum(salary)
from employees
group by rollup dept_id;
[case1], [case2] 가 같은 뜻의 구문이다.
하지만 [case1]은 from절이 두개나 작성되어 있어 성능은 [case2]가 더 좋다. ( [case2]는 from절이 1개라서 ..)
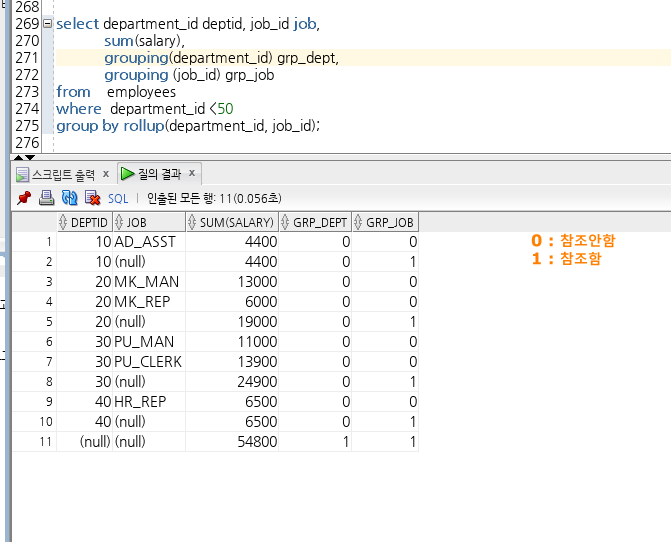
5. grouping
rollup 이나 cube로 생성된 null값과 DB에 저장된 null값을 구분할때 사용한다.
0일때는 해당 컬럼 참조안함, 1일때는 해당 컬럼 참조 이다.
'DB > Oracle' 카테고리의 다른 글
| Grouping sets (0) | 2022.09.22 |
|---|---|
| 상호관련 서브쿼리로 update,delete (0) | 2022.09.14 |
| Subquery로 데이터 조작 (0) | 2022.09.14 |
| with 절 (0) | 2022.09.14 |
| EXISTS 및 NOT EXISTS 연산자 사용 (0) | 2022.09.13 |



