
개발자 항해
집합 연산자 본문
1. union
쿼리구문 마다 select 해온 값을 중복 제외하고 모두 출력함

- 사용시 유의점
1) select 절이 컬럼 갯수가 맞아야한다.
emp_id, dept_id가 유형이 같아야하고 last_name과 d_name이 유형이 같야야한다.
왜냐하면 같은 컬럼에 나오기때문이다.
select emp_id, last_name
from emp
where d_id=50
union
select dept_id, d_name
from dept;
2) 이어서 쓸수 있고 이럴때는 우선 순위가 동등하다.
select emp_id, last_name
from emp
where d_id=50
union
select dept_id, d_name
from dept
minus
select dept_id, d_name
from dept
union all
select dept_id, d_name
from dept;
3) 괄호로 묶으면 우선순위를 변경할수 있다. () 안을 먼저 연산
select emp_id, last_name
from emp
where d_id=50
union
select dept_id, d_name
from dept
minus
(select dept_id, d_name
from dept
union all
select dept_id, d_name
from dept);
5) 가장 마지막에 order by 절 적음
select emp_id, last_name
from emp
where d_id=50
union
select dept_id, d_name
from dept
minus
(select dept_id, d_name
from dept
union all
select dept_id, d_name
from dept)
order by ....
5) 이런 연산의 경우 제목은 어떻게 되는가?
==> 첫번째 쿼리 구문의 컬럼명(emp_id, last_name)이나 alias 명이 출력된다.
정렬도 첫번째 컬럼기준.(emp_id나 last_name)
select emp_id, last_name
from emp
where d_id=50
union
select dept_id, d_name
from dept;
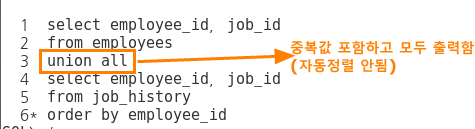
2. union all
중복값 포함하고 모두 출력한다.
(자동정렬 안됨)
3. intersect
양쪽 구문에 공통된 데이터를 출력
( 양쪽에 같은 데이터가 있는데 한번만 출력하므로 중복된 데이터를 제거하고 한번만 출력한다고 볼수있다.
그래서 자동정렬기능 포함)

4. minus
A쿼리 값에 B쿼리 값을 제외한 값을 출력시키겠다.

※ intersect, minus 비교



'DB > Oracle' 카테고리의 다른 글
| EXISTS 및 NOT EXISTS 연산자 사용 (0) | 2022.09.13 |
|---|---|
| Scalar Subquery (0) | 2022.09.08 |
| 순위 함수 (0) | 2022.09.02 |
| Top-N 관련 예제 문제 (0) | 2022.09.02 |
| Default DB에 접속, Default DB바꿔서 접속(리눅스) (0) | 2022.09.02 |



